
The potential for artificial intelligence (AI) and machine learning (ML) seems unlimited in its ability to discover and run new customer, business, operations, operations, environment, and social media. If your organization is to compete in the future, then AI should be at the forefront of your business.
Kearney research called “Impact of Analytics in 2020”Highlights unused profits and how businesses involve organizations seeking justification to improve their data technology (AI / ML) and data management:
- Researchers can make a profit of 20% if they are as effective as Leaders
- Followers can gain up to 55% off if they become effective as Leaders
- Laggards can make a profit of 81% if they are as effective as Leaders
The impact on business, systems, and social media can be overwhelming except for one major organizational problem – data. No less than AI godfather, Andrew Ng, saw a barrier to data and data management by empowering organizations and individuals to achieve AI and ML potential:
“The format and code of most programs are complex problems that have been solved. Now that the models are very advanced, we need to make that data work again.” – Andrew Ng
Data is the core of training AI and ML models. And high-quality, reliable information managed by dangerous and dangerous pipelines means that AI has the potential to impact these businesses and operations. Just as a healthy heart needs oxygen and reliable blood flow, so there is a steady stream of purified, accurate, rich, and reliable data needed for AI / ML engines.
For example, one CIO has a team of 500 data engineers who oversee more than 15,000 extraction, modification, and transport (ETL) operations that are responsible for acquiring, moving, integrating, organizing, and integrating data into 100s archives. privacy (data. marts, data warehouses, data lakes, and data warehouses). They operate in a multidisciplinary operational and customer-led system under strict multi-stakeholder agreements (SLAs) to support their multi-stakeholder diversification. It seems that Rube Goldberg may have been a data maker (Figure 1).

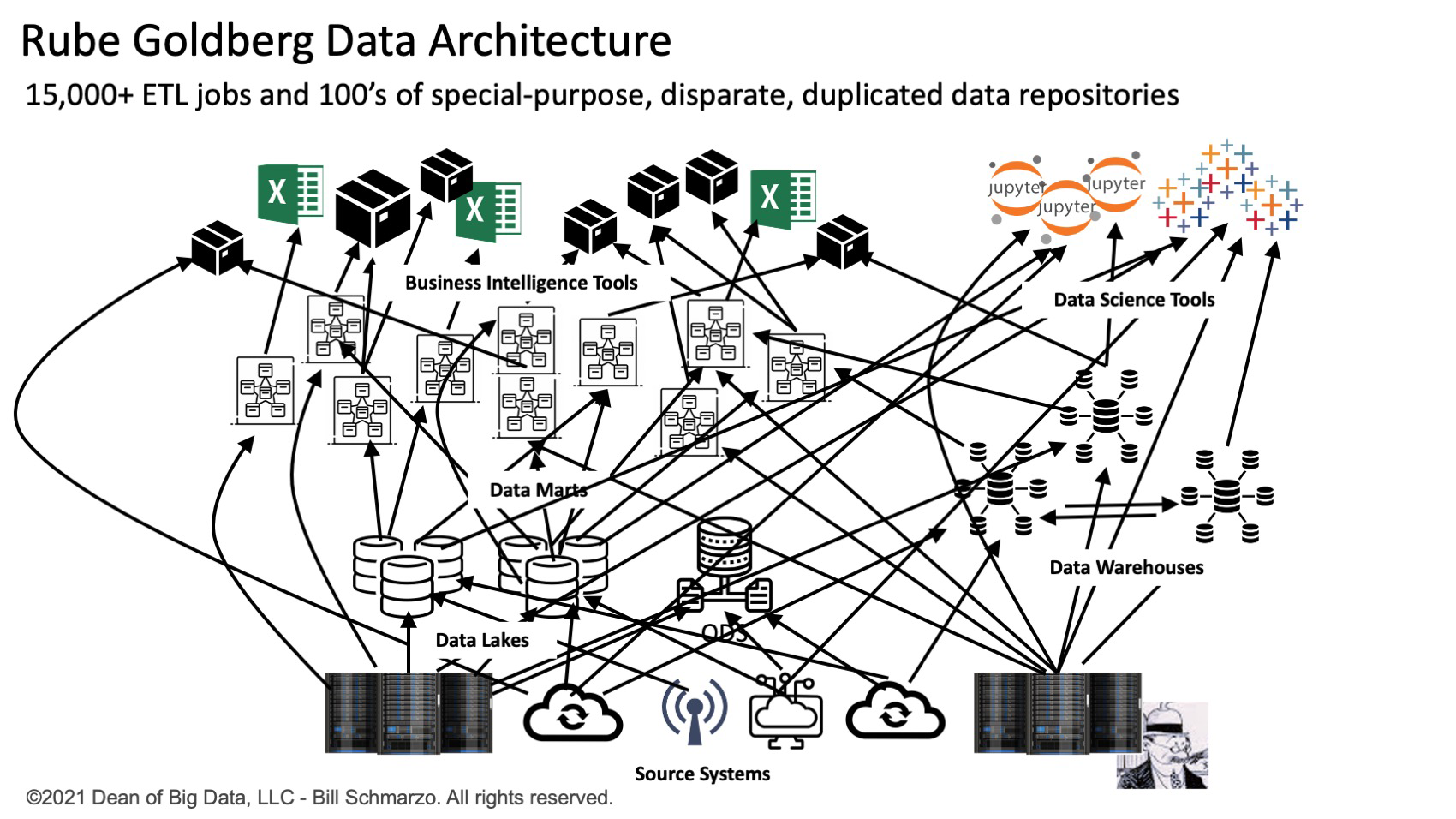
Reducing the spaghetti constraints of a single program, a specific goal, static ETL applications to move, clean, integrate, and modify data and severely hamper the “realization time” required for organizations to make the best use of a unique financial data model, “the most valuable treasure in the world“According to The Economist.
Outflow of smart data pipelines
The purpose of data pipelines is to modify and modify common and repetitive data acquisitions, transitions, transitions, and integration functions. A well-designed data pipeline system can speed up and modify settings related to collecting, cleaning, modifying, enriching, and moving data to low-end machines and applications. As the volume, diversity, and data flow increase, the demand for data cables that can grow consecutively within the cloud and cloud computing is increasing exponentially in business operations.
A data pipeline refers to a group of data processing events that integrate systems and businesses to analyze, modify, and enhance data. Data pipelines can occur at a predetermined time, in real time (download), or be triggered by predetermined rules or conditions.
In addition, concepts and algorithms can be developed in the data pipeline to create a “smart” data pipeline. Smart Pipelines are reusable and versatile resources that can be unique to startup machines and modify the necessary data to meet the unique needs and lighting of the system you want or use.
As machine learning with AutoML increases, data pipelines become more efficient. Data pipelines are able to move data between data enhancements and flexible modules, where neural network and machine learning systems can make high-level transitions and data improvements. These include segments, minimal analysis, classification, and production of high indices and maximum power.
Finally, one can integrate AI into data pipelines to be able to continuously learn and adapt according to sources, the necessary changes and enhancement of data, as well as the success of businesses and their performance in the machines they need.
For example: a smart medical pipeline can analyze medical teams (DRG) teams to confirm the consistency and completeness of DRG content and detect fraud when DRG data is moved by a data pipeline from a source. system to analytics systems.
Recognizing the value of a business
Big data agencies and data analysts are being challenged to demonstrate the value of the business of their data – using business data to solve financial problems.
Being able to access high quality, reliable data to the right consumer at the right time to guide timely and accurate decisions will be a major difference for the companies that own the data today. Rube Goldberg’s system of ELT records and private, specialized monitoring systems prevents organizations from achieving that goal.
Learn more about smart data pipelines in Modern Enterprise Data Pipelines (eBook) by Dell Technologies Pano.
This was developed by Dell Technologies. Not written by MIT Technology Review authors.